반응형
🖐 누락 데이터 확인
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()
df.info()
nan_deck = df['deck'].value_counts(dropna=False)
print(nan_deck)

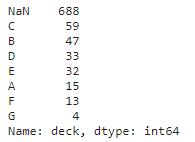
👉 'deck' 열에 NaN 값이 있음을 확인 / 'deck' 열에 있는 누락 데이터가 688개 라는 사실을 알 수 있음
🖐 누락 데이터 제거
import seaborn as sns
df = sns.load_dataset('titanic')
missing_df = df.isnull()
for col in missing_df.columns:
missing_count = missing_df[col].value_counts()
try:
print(col, ': ', missing_count[True])
except:
print(col, ': ', 0)
# NaN 값이 500개 이상인 열을 모두 삭제
df_thresh = df.dropna(axis=1, thresh=500)
print(df_thresh.columns)
# age 열에 나이 데이터가 없는 모든 행 삭제
df_age = df.dropna(subset=['age'], how='any', axis=0)
print(len(df_age))
🖐 누락 데이터 치환
# 평균으로 누락 데이터 바꾸기
print(df['age'].head(10))
print('\n')
mean_age = df['age'].mean(axis=0)
df['age'].fillna(mean_age, inplace=True)
print(df['age'].head(10))
# 가장 많이 나타나는 값으로 바꾸기
print(df['embark_town'][825:830])
most_freq = df['embark_town'].value_counts(dropna=True).idxmax()
print(most_freq)
df['embark_town'].fillna(most_freq, inplace=True)
print(df['embark_town'][825:830])
# 이웃하고 있는 값으로 바꾸기
import seaborn as sns
df = sns.load_dataset('titanic')
print(df['embark_town'][825:830])
df['embark_town'].fillna(method='ffill', inplace=True)
print(df['embark_town'][825:830])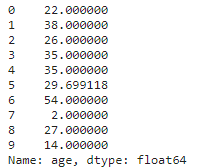


🖐 중복 데이터 처리
import pandas as pd
df = pd.DataFrame({'c1':['a','a','b','a','b'],
'c2':[1,1,1,2,2],
'c3':[1,1,2,2,2]})
print(df)
# 중복 데이터 확인
df_dup = df.duplicated()
print(df_dup)
col_dup = df['c2'].duplicated()
print(col_dup)
# 중복 데이터 제거
df2 = df.drop_duplicates()
print(df2)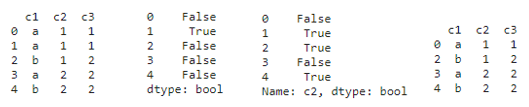
🖐 자료형 변환
import pandas as pd
df = pd.read_csv('/kaggle/input/autompg-dataset/auto-mpg.csv')
df.columns = ['mpg','cylinders','displacement','horsepower','weight','acceleration','model year','origin','name']
print(df.dtypes)
print(df['horsepower'].unique())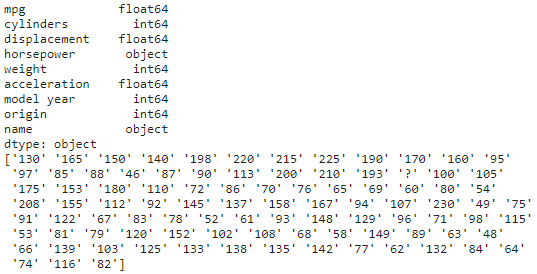
# 누락 데이터 삭제
import numpy as np
df['horsepower'].replace('?', np.nan, inplace=True) # '?'을 np.nan으로 변경
df.dropna(subset=['horsepower'], axis=0, inplace=True) # 누락 데이터 행 삭제
df['horsepower'] = df['horsepower'].astype('float') # 문자형을 실수형으로 변환
print(df['horsepower'].dtypes)
# float64
# 정수형 데이터를 문자열 데이터로 변환
print(df['origin'].unique())
df['origin'].replace({1:'USA', 2:'EU', 3:'JPN'}, inplace=True)
print(df['origin'].unique())
print(df['origin'].dtypes)
# [1 3 2]
# ['USA' 'JPN' 'EU']
# object🖐 필터링
import seaborn as sns
titanic = sns.load_dataset('titanic')
mask1 = (titanic.age >= 10) & (titanic.age < 20)
df_teenage = titanic.loc[mask1, :]
print(df_teenage)
import seaborn as sns
titanic = sns.load_dataset('titanic')
mask2 = (titanic.age < 10) & (titanic.sex == 'female')
df_female_under10 = titanic.loc[mask2, :]
print(df_female_under10.head())
import seaborn as sns
import pandas as pd
titanic = sns.load_dataset('titanic')
pd.set_option('display.max_columns',10) # 출력할 최대 열의 개수 설정
mask3 = titanic['sibsp'] == 3 # 함께 탑승한 형제 또는 배우자 수 3, 4, 5
mask4 = titanic['sibsp'] == 4
mask5 = titanic['sibsp'] == 5
df_boolean = titanic[mask3 | mask4 | mask5]
print(df_boolean.head())
🖐 데이터프레임 연결
import pandas as pd
df1 = pd.DataFrame({'a':['a0','a1','a2','a3'],
'b':['b0','b1','b2','b3'],
'c':['c0','c1','c2','c3']},
index=[0,1,2,3])
df2 = pd.DataFrame({'a':['a2','a3','a4','a5'],
'b':['b2','b3','b4','b5'],
'c':['c2','c3','c4','b5'],
'd':['d2','d3','d4','d5']},
index=[2,3,4,5])
print(df1, '\n')
print(df2, '\n')
result1 = pd.concat([df1, df2])
print(result1, '\n')
result2 = pd.concat([df1, df2], ignore_index=True)
print(result2, '\n')
👉 df1, df2 연결하면 df1의 0,1,2,3 행에는 'd' 열이 없기 때문에 NaN 으로 입력
👉 ignore_index 옵션 추가 시, 기존 행 인덱스를 무시하고 새로운 행 인덱스를 설정
# 2개의 dataframe을 좌우 열 방향으로 이어 붙이듯 연결하기
result3 = pd.concat([df1, df2], axis=1)
print(result3, '\n')
# join='inner' 옵션 적용 (교집합)
result3_in = pd.concat([df1, df2], axis=1, join='inner')
print(result3_in, '\n')
반응형
'Python' 카테고리의 다른 글
| [Python] Pandas _ Time Series (0) | 2023.08.24 |
|---|---|
| [Python] Pandas _ Apply, Map (0) | 2023.08.24 |
| [Python] Pandas data: auto-mpg data 시각화 (0) | 2023.04.30 |
| [Python] matplotlib, seaborn 막대그래프 그리기 / 꾸미기 (0) | 2023.04.17 |
| [Python] docstring (문서화 / 사용자 정의 함수 ) (0) | 2023.04.13 |


